

This is an excerpt from the book Computer Programming: An Introduction for the Scientifically Inclined.
Computers
Where a calculator on the ENIAC is equipped with 18,000 vacuum tubes and weighs 30 tons, computers in the future may have only 1,000 vacuum tubes and perhaps weigh 1 ½ tons.
Popular Mechanics, March 1949
Do You Need To Know?
Many programming teachers deliberately refrain from going into details about computer hardware. Their reasoning is that intimate knowledge of the way computers work actually hinders the development of a proper programming style. In fact, many prefer working with pencil and paper instead of even using a computer. A quote by Edsger W. Dijkstra, a famous Dutch computer scientist, is that “Computer Science is no more about computers than astronomy is about telescopes.” This is why the term ‘computer science’ is rather misleading. Some people have therefore adopted the slightly different term ‘computing science’.
But this book is not about computer science. Instead, it treats computers in the same way an astronomer might treat telescopes. It certainly makes sense for an astronomer to know how telescopes work, and understand the basics of optics. Computers to us are tools, and any craftsman will explain to you that a thorough understanding of your tools can be vitally important.
Another famous quote is that it shouldn't matter whether your programs are performed by computers or by Tibetan monks. While this is certainly true, ‘we scientists’ are not necessarily in the business of creating the most elegant programs that would thrill Tibetan monks reading them. Our job is to get some kind of calculation finished—preferably before our computation time on the faculty's super computer reaches our quota. When our methods to achieve that goal resemble fastening a screw with a hammer, so be it.
On the other hand, it is worthwhile to keep the Tibetan monk quote in mind. Because surprisingly often, the program that a monk would be happiest to perform, is also the best solution.
Hardware Overview
Processor
The ‘brain’ of a computer is formed by the Central Processing Unit, or CPU, also simply called ‘the processor’. The CPU can actually only do surprisingly simple things, but it can do it very fast. What a CPU does is execute a list of instructions which it fetches from memory. These instructions form the so-called ‘machine language’. They are the smallest ‘building blocks’ of a program. The atoms, if you will.1
Examples of the kind of instructions a CPU can perform are ‘retrieve the contents of memory location p’, ‘compare this value to zero’, ‘add these two values’, ‘store this value in memory location p’, ‘continue running the program from memory location p’, etc. Everything more ‘high-level’ that a computer does, is expressed in lists of instructions of this very simple kind. Things like ‘print this file’, ‘store these data on disk’, ‘check whether the user has pressed a key’, or ‘plot these data in a graph on screen’ are totally alien to the CPU and need to be expressed in machine language programs that can be hundreds or thousands of instructions long. Don't worry though, you won't need to write those. We can use higher-level programming languages and libraries that provide an abstraction layer above the machine language level.
Machine language is usually referred to as second generation
programming language, the
first generation being the actual (binary) codes. The translation of
more-or-less human-readable instructions to the actual machine codes is
done using an assembler. The human-readable
machine language instructions are called mnemonics,
because they are easier to remember than the actual codes. So, the
assembler might translate an instruction like ADD A,(HL) into
10000110.2
A third generation programming language, which is the type we
will be focusing on here, offers an even higher level of abstraction
with named variables, English-like syntax, etc., which would let you
write instructions like ‘print y’ or ‘result
= (1 + epsilon)*sin(x)’. Translation of your third-generation program
into something the machine can handle is done by either a compiler
or an interpreter—we'll get back to this later.
Research on fourth generation programming languages is in full swing; these would let you write ‘meta-programs’ like ‘Write me a program to calculate the energy levels in a single quantum well with variable parameters.’ Unfortunately, we're not quite there yet.
Typically, a CPU has in the order of a few dozen to about one hundred different instructions. The first processors did not even have instructions to, say, ‘multiply these two values’; instead, this needed to be explicitly implemented in lower level instructions (using repeated addition, for example). Although modern processors can have quite elaborate instructions that multiply vectors or compare two values and exchange them, the real power of processors is that they are fast. Typically, they can process millions of these instructions per second, with billions being no exception.
The speed of processors is often measured in Hertz. The value you often see quoted for a certain computer system is their clock frequency. One ‘clock tick’ is the smallest time slice a system can operate with. This is actually not a very good measure to compare different types of processors. The problem is that different types of instructions can take a different number of clock ticks to perform, so the clock speed is not trivially related to the number of instructions per second the processor can perform. There is a measure of processor performance called MIPS (million instructions per second) which for this reason is also known as ‘meaningless indication of processor speed’.
Memory
Computers store, retrieve, and operate on data. These data are stored in some form of memory. To write efficient programs, it is important to understand that a computer has a form of memory hierarchy. There are different kinds of memory in a system, each with different properties.
The fastest kind of memory available to a computer are its
registers. These are located in the processor itself, and can
often be accessed in a single clock tick. Usually, the processor has
relatively few of them available, in the order of only four to 128 or even
256 in more advanced processor architectures. Usually it is in the
order of 32. The ‘size’ of these registers (determining the range
of numbers they can store) is dependent on the architecture of the
processor. For example, when a processor is said to be 32 bit,
the main registers of that processor are 32 bits in size, and it can
usually address 232 bytes of memory (hence 4 gigabytes
is the upper limit of the memory size of a 32-bit machine).
The ‘normal’, or ‘working’ memory of a computer is called
RAM, for ‘Random Access Memory’. One can view
memory as a (large) array of locations that can each store a
value. The locations are numbered, and this number is called
the address of the memory location.
The smallest ‘addressable’ memory unit is the byte. Each byte
consists of eight bits (binary digits).3
These bits can have only two values: 1 or 0 (or `on' or `off',
if you wish). Since a byte has 8 bits, it can store any integer value
between 0 (all bits are 0) through 28 - 1 = 255 (all bits are 1).
See the section about binary arithmetic if this doesn't make
sense to you.
To handle larger numbers, bytes can be grouped together to form a
16-bit word (storing up to 216 - 1 = 65535) or a 32 bit
long word (storing up to 232 - 1 = 4294967295). On
64-bit systems, there also is a long long word, combining 8 bytes.
It is dangerous to mention typical memory sizes since that will make this
book look hopelessly outdated in only a few years' time, but at the time
of writing, memory capacities of a few gigabytes
It is important to realize that RAM is relatively slow. Although memory technology progresses and memory is getting faster, processors have accelerated far quicker. Typically, retrieving the contents of a memory location in RAM takes in the order of 10 ns. Compare this to a clock tick cycle of 3 ns in a 1 GHz system. The processor would spend most of its time waiting for data to become available from memory.
To remedy this problem, cache memory was introduced. This is memory that acts as an ‘intermediate’. It is fast (in the order of, say, 3 ns) but also far more expensive than ‘normal’ memory, and therefore a typical system has far less of it. The way it works is that it stores data as a buffer between the CPU and main memory. If the CPU asks for the contents of a certain memory location, the memory subsystem first checks to see whether it happens to be in the cache memory, and only retrieves it from main memory if not (and stores it in the cache too, overwriting ‘older’ data there). Since many computer programs look at the same data more than once, next time that data is requested a lot of time can be saved because it is still in the cache memory. Most computer systems have several levels of cache memory, usually ‘level 1 cache’ directly on the CPU, running at the same speed as the CPU itself (or, say, half of that), or ‘level 2 cache’ which is slightly slower (and cheaper, and thus larger). Typical values are to the order of 32 kilobytes of level 1 cache and a megabyte for level 2 cache. There is actually even more cleverness involved in the way cache memories work (for example, RAM often is more efficient if it is asked for the contents of several adjacent memory locations in one ‘burst’, so the memory subsystem could gather more data than it is asked for at the time and store it in the cache, based on the prediction that the CPU might need that data in the near future anyway). For more information, you can take a look at more specialized literature like [5].
Whereas cache operation is completely transparent to the programmer (i.e., you don't need to know it's there), programs can run much faster (up to an order of magnitude) if the program and the data it operates on ‘fit’ in the cache.
It is also quite important to recognize that the types of memory mentioned so far are volatile. That is to say, this memory only ‘remembers’ its contents while the system is switched on. Often, you would like to store data for a longer period of time. There are different types of memory which are persistent, such as a hard disk, CD-ROM, or flash storage.
Typically, capacities of the persistent storage available to a computer system are far larger than the RAM size. Consumer-level hard disks have capacities in the terabyte-order. It also needs to be noted that this kind of storage is several orders of magnitude slower still than RAM. When you are operating on data sets that are really large (so they won't fit in RAM), this is something to take into account. For several areas of science (such as astronomy or experimental high-energy physics), huge data sets are the rule.
Hard disks come in two major flavors, IDE and SCSI. The former stands for ‘Integrated Drive Electronics’ and is traditionally common on personal computers, while the latter stands for ‘Small Computer Systems Interface’ and is the system of choice for multi-user or high-performance computers. Traditionally, IDE drives have been cheaper but slower, and SCSI has offered some nice advantages like being able to chain more devices together, and offer ‘redundant storage systems’ (i.e., store the same data multiple times, so that when one drive breaks down, the data is not lost). IDE has caught up quite nicely, and although the fastest and meanest disk drives are still SCSI, IDE suffices for most applications; especially with the advent of high-speed ‘Serial ATA’ (ATA is the ‘official name’ for what everyone calls IDE). Again, this difference probably does not need to concern you unless you are deciding on a hardware system for your specific experiment or calculations. If your application involves huge amounts of measurement data that need to be stored in real time, you should consider equipping your system with SCSI. For completeness, it should also be mentioned that SCSI is not limited to hard disks only, as there are other peripherals (like scanners) which connect to the system via SCSI, although this is superseded with USB and FireWire (see below).
Peripherals and Interfaces
Of course, there need to be ways to get information into a computer and ways to view results. Typically, a computer has several input devices like a keyboard or a mouse, and output devices like a monitor or a printer.
In experimental science, computers are often also used for controlling an experimental set-up, or for data-acquisition. For this, there are a variety of ways to interface (‘talk’) to the computer. For relatively slow connections, with data rates in the order of up to 10 kilobytes/second, it is often easy to use the serial port. ‘Serial’ means that the data bits are transferred one after another, as opposed to ‘parallel’, when multiple bits (mostly 8, or some multiple of 8) are transferred simultaneously. Obviously, a parallel port requires more physical wires. Traditionally, printers have been connected to computers using a parallel interface.
Most computers have several serial ports available which operate following the RS-232 standard. This is quite a popular interface because it is both well documented and relatively easy to implement with cheap off-the-shelf electronics, and runs at speeds up to 115 kilobits/second (230 or even 460 on some systems). As an example, most external modems work via this interface.
Incidentally, ‘legacy’ parallel and serial interfaces are slowly being replaced by more modern interfaces such as USB (see below). This has the benefit of not having lots of different interfaces which can each take at most one or two devices, having special interfaces for your keyboard, mouse, modem, etc. The drawback is that the modern interfaces are more complex and need integrated circuitry to connect, whereas the ‘old’ interfaces can easily be used in an experimental setup using an old-fashioned soldering iron and a simple wiring diagram.
On the other end of the spectrum are high-data-rate interfaces such as GPIB which require installing separate extension cards in the computer, driven by special software, but enabling far higher throughput. This is needed to do real-time readouts of oscilloscopes, for example, with sampling rates up to the order of 100 MHz or more.
In between of these extremes, there are interfaces such as USB (Universal Serial Bus) and FireWire (officially called IEEE 1394), which several more recent peripherals and/or measurement systems are supporting. These interfaces support ‘hot-plugging’, i.e., the peripherals can be connected and disconnected while the system is switched on, and are detected and configured ‘on the fly’. There is a trend towards using ethernet as an interface to peripherals (especially more ‘elaborate’ devices); they often include a small embedded computer which is configurable via a ‘web interface’.
It is important to note that often, measurement equipment produces data in analog form, which needs to be converted to the digital form which a computer can work with. Many data acquisition cards have analog-digital converters that can convert hundreds of millions of samples per second.
In a pinch, it is worth noting that a very cheap and easy-to-use digital-to-analog and analog-to-digital converter is present in almost any consumer-level personal computer in the form of its sound card. Whereas this is probably not suited for serious lab work due to the limited amount of sample frequencies it can work with and its resolution, it has been used successfully in a wide range of high-school or first-year science lab type experiments.
Networks and Clustering
To get more computing power, you could get a bigger computer, but you could also try to somehow connect multiple computers together in a network, forming a cluster. This approach doesn't always work; only when the specific calculations you need to do lend themselves to be split up in multiple, independent parts, which can then be calculated on separate computers. This is of no use when each of your calculations depends on the outcome of a previous one, since the computers in your cluster would spend their precious time waiting for another computer to finish its calculation, then do their part of the job, and finally hand off the result to the next. Also, there is considerable ‘overhead’ associated with splitting up the calculations. Network connections are slower than intra-computer connections, so sending lots of data back and forth is going to take a relatively long time. Only for large and time-consuming calculations involving relatively little data, it is worthwhile to use multiple computers.Excellent examples of this ‘distributed computing’ on a very large scale are the ‘SETI at home’ project and the RC5 project. Both harness the ‘spare computer cycles’ of computers all over the Internet, using computers which their owners have registered with the project maintainers. The former project searches for extra-terrestrial intelligence by handing out packets of radio frequency readings to (home) computers, which then run a data analysis program on it when they would otherwise be sitting idle, and send the results back to the project maintainers (and then receive a new set, etc.). The latter project was more of a ‘proof of concept’, and was successfully used to crack a certain encryption scheme by brute force which would have taken tens of years in a conventional approach.
On a smaller scale, computer animation as used in films is often performed on clusters of computers called ‘render farms’, comprising hundreds of relatively low-cost computers and dramatically speeding up the rendering process.
Also, it is quite customary for computers to have more than one CPU, or have CPUs which internally have multiple complete processing units (so-called multi-core processors). This is an especially cost-effective way of increasing computer power, as prices increase exponentially with CPU speed (and CPU designers are running into physical limits regarding their clock speed) whereas performance increases only linearly. Performance does not scale exactly linearly with the number of CPUs though, since there is an overhead as well. Depending on the nature of the calculation and on how well the hardware and the operating system can cope with multiple CPUs, adding a second identical CPU will yield anywhere between 1.5 – 1.9 times the performance. Also, this extra performance does not come ‘free’: The programmer will have to make specific adjustments to the program to make it use the available CPUs.
Binary Arithmetic
Whereas most people use the decimal system, computers use a binary
system. In this system, there are only two digits: 0 and 1. In our
day-to-day decimal system, we are used to the fact that the
position of a digit within a number determines its ‘weight’
when determining the value. The rightmost digit designates the ‘ones’,
the one immediately to its left the ‘tens’, then the
‘hundreds’, etcetera. Formally, the value of a decimal number of
n digits, numbered from right to left(!) as
dn...
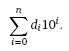
So, the interpretation of the number 3207 in the decimal system is (going from right to left): 7 times 100 (7), plus 0 times 101 (0), plus 2 times 102 (200), plus 3 times 103 (3000), equals three thousand two hundred and seven. This is so trivial you don't usually stop to think about it.
Quite similarly, in the binary system, the rightmost digit designates the ‘ones’, the one immediately to its left the ‘twos’, then the ‘fours’, etc. So, for a binary number the formal interpretation would be
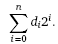
As an example, the interpretation of the binary number 1101 is (again, going from right to left): 1 time 20 (1), plus 0 times 21 (0), plus 1 time 22 (4), plus 1 time 23 (8), equals thirteen.
In the same way that powers of ten form ‘natural orders of magnitude’ for (most) humans, so are powers of two the ‘natural orders of magnitude’ for binary systems.
There is another system in regular use in computing, which is the hexadecimal system (often simply called ‘hex’). This is a base-16 system, so it has a few extra digits besides our usual 0 – 9. In the hexadecimal system, these are designated using letters:
| Hex | Decimal |
| A | 10 |
| B | 11 |
| C | 12 |
| D | 13 |
| E | 14 |
| F | 15 |
Hence, the hexadecimal number 3E8B is interpreted as ‘B’ times 160 (i.e., 11 times 1), plus 8 times 161, plus ‘E’ times 162 (i.e., 14 times 256), plus 3 times 163, equals sixteen thousand and eleven (16011 in decimal). To differentiate hexadecimal from decimal numbers, they are often prefixed with ‘0x’ (that's zero-x) or postfixed with ‘H’. The above number would then be written as either 0x3E8B or 3E8BH. The hexadecimal system is not actually used by the computer itself, but rather in computer programming because the relation to binary values is clearer than when decimal numbers are used.
Negative Values
In our decimal system, we have a ‘special digit’ which can only occur at the leftmost position in a number, and which designates negative numbers. The previous sentence is, of course, just a convoluted description of the minus sign. In the binary system, there is no such special digit, and so far we have only seen how to represent positive integers (or zero) in binary. Clearly, there is a use for negative numbers, and there are several ways to represent them. The most often used system is called two's complement. It uses one bit (the leftmost) as a sign bit, using 0 for positive and 1 for negative. Also, to negate a number, each 1 in the binary representation is replaced with a 0 and vice versa, and finally 1 is added to the result. The main advantage of this ‘agreement’ is that you can subsequently perform arithmetic on these numbers without having to treat negative values in a ‘special’ way.So, to negate the 8-bit binary value 00101101, we would first get 11010010, and then add 1 to the result, getting 11010011. Using this system, the largest negative value representable in 8 bits is -127 in decimal: ‘minus’ 01111111 becomes 10000001. The largest positive value is then 128 decimal; anything larger would have the 7th bit and another bit set, which would make it be interpreted as negative.
Therefore, it is important to realize that seeing only the digits of a certain binary number, say 11010011, doesn't tell you whether this number represents 211 or -45.
Incidentally, there is another system called one's complement in which a negative value is simply formed by inverting all the bits (i.e., without adding one). This system has the drawback that there are two ways of representing ‘zero’, namely ‘all bits cleared’ but also ‘all bits set’. The latter would correspond to ‘minus zero’. This ambiguity has led to the adoption of two's complement instead in the majority of systems.
Floating Point Numbers
Apart from integer numbers of various sizes, computers can also work with floating point numbers, often simply called floats, or, in some computer languages, reals. It is quite important for scientific programming to realize that computer reals are not ‘real’ reals, in that they have a finite precision. More on that, and why it is important, in the next subsection.The way a computer stores floating point values is rather clever because it allows a wide range of values to be stored in the same number of bits. Of course, to us scientists it is actually nothing new, as we often use a similar trick when dealing with either very large or very small numbers: We note a certain factor (with a certain precision) and add ‘times ten to the power of n’. For floating point values, the computer simply divides the available space in two parts, and stores the factor (called the mantissa) in one part, and the exponent in the other. Both are signed with a single bit. Most systems offer two or even three varieties of floating point number types, with increasing numbers of bits available for increased accuracy, in a tradeoff for memory requirements and/or execution speed.
Range and Accuracy
For the integer types (bytes, words, and long words) it is quite obvious that there is a limit to the actual value they can store. Trying to store 70000 in a 16-bit word simply won't fit. Nor will 40000 in a 16-bit signed word. Trying to do so anyway will result in the computer signaling an error condition called overflow. What specific type of variable you will need to use in your programs to prevent this phenomenon looks to be simple enough at first sight. However, you must realize that this limit also has an effect on intermediate results.As an example, consider you are writing a program to calculate the average distance to the sun for all the planets of our solar system. You decide to use integer variables (just for the sake of the argument), and since a quick glance at the distances table learns that the average probably comes out at about 2×109 km, you decide that it is safe to use 32-bit, unsigned integers (since these can hold over 4×109).
Now, depending on how you write your computer program, you might still run into trouble. If you would do it the ‘naive’ way, by simply adding up the various distances from the sun for each of the planets, and finally dividing by nine to get the average value, an overflow will occur during the calculation. This is because the sum of all these distances is close to 1.6×1010 km, and that intermediate result doesn't fit, no matter whether you are going to be dividing it into something more manageable later on.
Of course, the correct thing to do in this rather contrived example would be to use floating point values. They are called ‘floating point’ for a reason: when the value grows ‘too big’, the exponent changes to keep the mantissa within range. You can view it as if a float value ‘resizes to fit’. For most systems, even the smallest type of floats can vary between 10-37 and 10+38, and the mantissa has 24 digits of precision. If that is not enough, there is usually a ‘double precision float’ (or simply ‘double’) available, that often goes from 10-308 to 10+308 with 53 digits of precision.
However, it is important to realize that floats have a finite precision. For a human, the question ‘how much is 10100 + 1?’ is just as easy to answer as ‘how much is 1010 + 1?’ or ‘how much is 10200 + 1?’. For the computer, though, these pathological numbers pose a problem. Because they are big, the exponent shifts to make room (or ‘the point floats’, if you will), but adding that 1 will then be problematic because there is not enough precision left. This results in the somewhat disturbing conclusion that to a computer, N + 1 = N, for sufficiently large N.
It is quite important to keep these anomalies in mind when designing scientific computer programs.
Rational and Complex Numbers
Although some computer languages also have a special type of variable for storing complex numbers, many do not. This was added to the C standard relatively late (and not all compilers support it yet). This is one of the reasons scientists usually scoffed at computer scientists trying to sell them C over FORTRAN (which has had complex numbers for ages, as well as high-precision floats). We will see that it doesn't really matter as you can add your own types to most serious programming languages (including, in a limited and somewhat concocted way, C).A more fundamental issue is that computers tend not to know about rational numbers. To a computer, ½ = 0.5, no matter how much the difference has been beaten into our heads at school (saying that ½ is ‘infinitely precise’ and that 0.5 represents anything between 0.45000... and 0.54999...). The computer cannot accurately represent 1/3, for example. That means that there are fundamental rounding errors that could possibly cause trouble. This phenomenon is investigated later in this book.
Now, it needs to be said that with clever programming, one can make computers work with rational numbers (in fact, they can do algebra just fine). This has even appeared in the realm of handheld calculators. But at the lowest (hardware) level, the most advanced type of numbers a computer ‘knows’ about are floats (or possibly vectors of them, in more modern machines).
Operating Systems
The operating system your scientific program runs on is usually even less of an issue than the particular computer hardware. There is one notable exception which is in experiment control, which is why we will briefly dwell on the subject.
The first (big) programmable computers were quite literally ‘re-wired’ for each new program. The operator would plug in cables, like an old-style telephone operator. Later, computers were re-programmable more easily by reading the programs from punch cards. These computers were operated in batch mode. That is to say, the programmer would write a program (usually in a low-level language at that time), get it punched in a stack of punch cards, and hand this to the computer operator. When it was this program's turn to run, the operator would load the program into the computer, run it, and when it was done, collect the output and run the next one.
This method of running computers turned out not to be the most efficient one, since when a program was loading a large data set off a (relatively slow) storage medium, the CPU would just sit there, twiddling its expensive thumbs waiting for that operation to finish.
With the advent of faster and larger memory, computers could hold several programs in memory at once, and ‘switch’ between them. I.e., when one program would issue a ‘slow’ operation, the computer would pay attention to another program while, for example, the disk was loading the requested information into memory for the first program. Once that was done, the computer would switch back to the first one. This ensured that the CPU was always running at full throttle.
Running several programs ‘at once’ (note that it wasn't really ‘at once’, but rather ‘small parts of them in rapid succession’) introduced all kinds of other problems—for example, when one of the programs would have an error in it, say, overwriting the contents of random memory locations, other programs running along with it could be influenced by that, producing erroneous results, even though they were themselves fully correct.
Another problem is that of limited resources; suppose two programs request a chunk of memory for intermediate results 3/4 the size of the total memory. Were each of these running on the machine alone, this would not be a problem. But when running on the same machine simultaneously, the second program trying to get the requested chunk of memory would somehow have to be either told this failed, or suspended until the first program finished with it. The same goes for multiple processes requesting access to, say, a plotter or printer connected to the computer.
So, gradually the operating system expanded from a simple scheduler for various jobs, into a complex system taking care of memory management, resource allocation, etc. It also provides a variety of services to programs, such as ‘abstracting’ various types of computer hardware (so that your program does not need to know exactly what kind of sound card the computer system has, or what video card, etc.), and provides support for showing your program's output in a window on screen, which the user can move, resize, etc. It also takes care of file management on the computer's hard disks, provides network connections (to other machines on your local network or to the Internet), and much more. It is safe to say that for the vast majority of computers nowadays, the operating system itself is probably the most complex piece of software running on it.
Usually, an operating system tries to be as transparent as possible, programs would spend most of their time running as if they were the only program on the system, apart from some ‘agreements’ that a program never accesses hardware directly, but always ‘asks’ the operating system for it (to prevent the limited resources problem mentioned above), etc.
However, there are some situations in which it is important to realize that running on a system together with other programs imposes subtle differences with having the system all to yourself. Suppose the computer is being used to drive some kind of experimental set-up in which some apparatus is controlled, and some measurement data needs to be collected a certain amount of time after an event occurs. There are plenty of examples for such a set-up, such as firing a laser into a cell containing a gas mixture, and reading an image from a CCD camera exactly x milliseconds later.
Now, your computer program might in broad lines be structured like this:
- 1. Fire laser
- 2. Wait x milliseconds
- 3. Read data from camera
which looks easy enough. However, if the operating system decides to interrupt your program after it has just fired the laser, then turn its attention to several other jobs running on the same computer (for example, because you have moved the mouse, or because some network activity was detected and the computer needs to store incoming data somewhere, or whatever else might be going on on your computer), and only returns to your experiment-driving program a couple of milliseconds later, the data read in from the camera would be ‘stale’.
Because of this problem, there exists a special class of operating systems called real time operating systems, which make certain guarantees about how long certain operations will take at most. In such an operating system, you could ask to wait exactly x milliseconds, and while the system would be free to do other stuff in that time span, it guarantees it will return to your program within that limit.
While this all may seem rather trivial, it is surprising how many experiments are driven using a computer running an operating system that is thoroughly unsuited for that task.
For an excellent text on operating systems, see [6].
Specialized Machines
It is worth mentioning that there are specialized computers that can do a certain type of operations very efficiently. For example, some computers have special arithmetic units that can perform calculations on whole vectors at a time. In many areas of science, vector (and matrix) calculations form an important part of daily life, and thus a machine which can speed up these calculations can save a lot of time. Another example is parallelism, i.e., having multiple CPUs running simultaneously.
Some of these ‘extras’ are handled transparently to the programmer by the operating system (for example, by scheduling different concurrent processes to various processors) or by the specific programming language used or the compiler used to translate it to machine code (for example, the compiler might recognize that you are doing vector arithmetic and could insert built-in machine code instructions for these). However, sometimes the programmer needs to specifically use these advanced features.
Although it is outside the scope of this book to dwell on these specialized subjects too long, it is worth noting that several of these features, which used to be strictly the domain of high-end computers, are finding their way to the user desktop as well. Machines with two or more processors in them are available off-the-shelf (although it is not unusual for high-end computers to have 64 processors or even more), and many processors have used ideas from vector-processing systems in their instruction set, usually under the name of ‘multimedia extensions’ or some-such.
Synopsis
Whereas designing your programs as machine-independent as possible will generally result in more elegant programs, blatantly ignoring the features and limitations of computers could result in inefficient programs, or even incorrect and unexpected results.
This chapter gave a brief overview of computer hardware and operating systems, and pointed out some pitfalls to avoid when designing scientific programs.
Also, computer arithmetic and native data types were explained, along with some caveats as to precision and range of them.
Questions and Exercises
1.1 Write your birth year in binary and hexadecimal notations.
1.2 Most procesors have specialized circuitry for performing multiplications, and the specific values of the operands of a multiplication do not make much difference in the speed at which the operation is performed. However, ‘older’ computers could multiply by a factor of 2n significantly faster than by a factor of, say, 3n or 7n. Can you explain why? Hint: can you multiply by a factor of 10n faster than by a factor of 3n or 7n?
1.3 To get a feeling for data acquisition and the data rates involved, calculate
how many bytes per second are transferred when capturing audio at CD
quality (which is sampled at 44.1 kHz, 16 bits per sample, stereo). Could this
be transferred over a serial connection as mentioned above,
without any compression techniques?
Footnotes
HL to the accumulator
register A” in the machine code of the Zilog Z80 processor, as
found in the Sinclair ZX80 and later computers (most notably the ZX Spectrum and
the Tandy TRS80).